3 月 10日,字節豆包大模型團隊官宣開源一項針對 MoE 架構的關鍵優化技術,可將大模型訓練效率提升1.7倍,成本節省40%。據悉,該技術已實際應用于字節的萬卡集群訓練,累計幫助節省了數百萬 GPU 小時訓練算力。
MoE 是當前大模型的主流架構,但其在分布式訓練中存在大量跨設備通信開銷,嚴重制約了大模型訓練效率和成本。以海外主流模型Mixtral-8x7B為例, 其訓練過程中通信時間占比可高達 40%。針對這一難題,字節在內部研發了COMET計算-通信重疊技術,通過多項創新,大幅壓縮了MoE專家通信空轉時間。
相較DeepSeek近期開源的DualPipe等MoE優化方案,COMET可以像插件一樣直接接入已有的MoE訓練框架,支持業界絕大部分主流大模型,無需對訓練框架進行侵入式改動。因簡潔、通用的設計理念,該工作以5/5/5/4 的高分入選全球機器學習系統頂級會議 MLSys 2025 ,被認為“在大規模生產環境中極具應用潛力”。
具體而言, COMET 從系統層面建立了面向 MoE 的細粒度流水線編程方式,通過引入共享張量依賴解析、自適應負載分配兩項關鍵機制,來解決通信與計算之間的粒度錯配問題,并精準平衡通信與計算負載,最終大幅提升MoE流水線整體效率。 引入COMET后,單個 MoE 層上可實現 1.96 倍加速、端到端平均 1.71 倍效率提升,且在不同并行策略、輸入規模及硬件環境下均表現穩定。
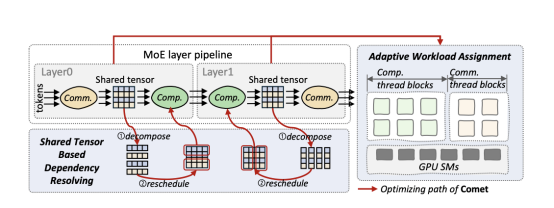
COMET 的設計結構
COMET 與Deepseek 研發的DualPipe方案還可以聯合使用。在降低MoE通信開銷上,COMET 采用了計算-通信融合算子的優化方式, DualPipe則通過排布算子來掩蓋通信,兩種方案并不沖突,結合使用或將更大幅度壓縮模型訓練成本。
目前,COMET支持多種MoE并行模式,部署靈活、方便。同時,COMET核心代碼已開源,并向開發者提供了一套友好的 Python API,計劃兼容 Triton 等編譯生態。
COMET論文鏈接:https://arxiv.org/pdf/2502.19811
開源地址:https://github.com/bytedance/flux