騰訊近日正式揭曉了其最新研發(fā)成果——混元新一代快思考模型Turbo S。這一創(chuàng)新模型的問世,標志著騰訊在人工智能領(lǐng)域邁出了重要一步。
據(jù)騰訊官方介紹,Turbo S與以往的慢思考模型,如Deepseek R1和混元T1,有著本質(zhì)的區(qū)別。它能夠?qū)崿F(xiàn)“秒回”,顯著提升了答案的輸出速度。具體而言,Turbo S的吐字速度較之前提升了一倍,首字時延更是降低了44%,為用戶帶來了更加流暢和即時的交互體驗。
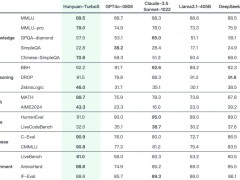
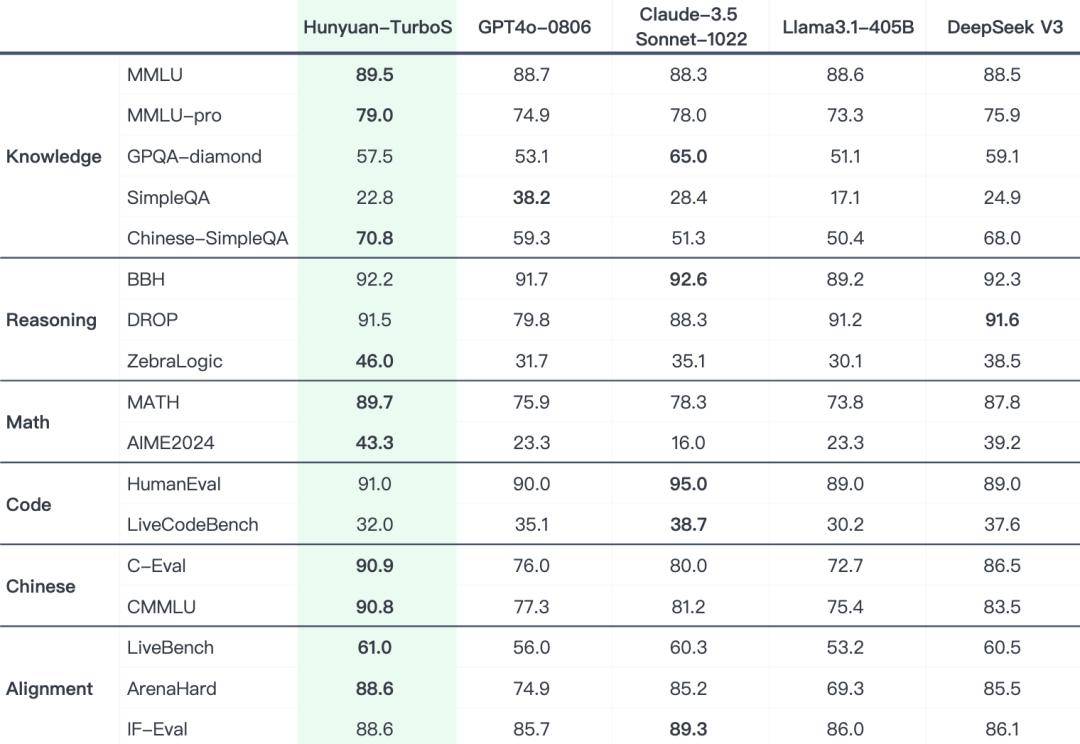
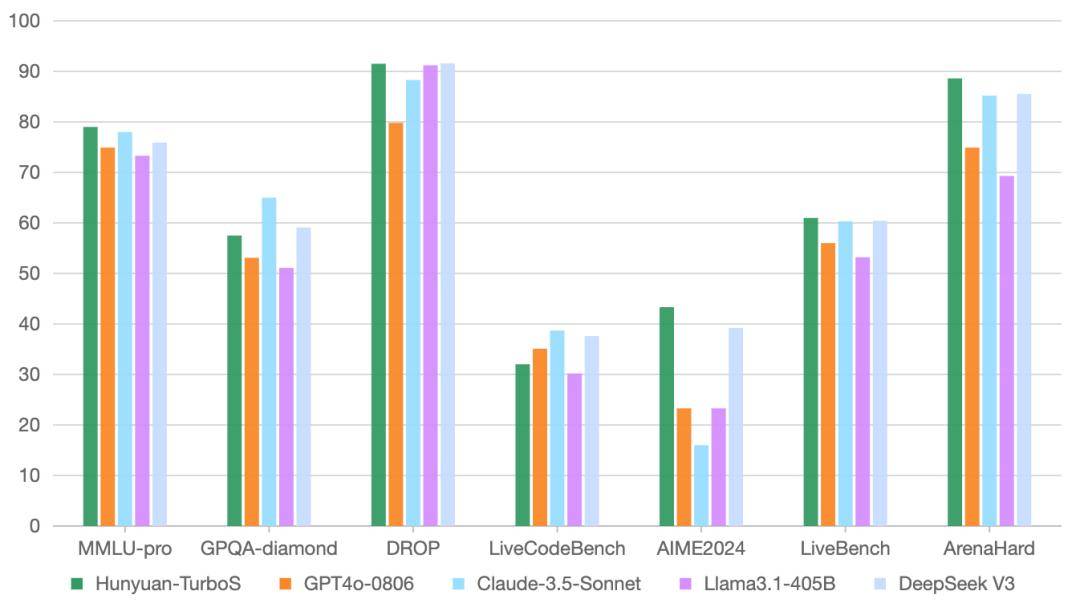
在業(yè)界公認的多個公開基準測試中,Turbo S展現(xiàn)出了令人矚目的表現(xiàn)。在知識、數(shù)學、推理等多個領(lǐng)域,它的效果堪與DeepSeek V3、GPT 4o、Claude等一系列業(yè)界領(lǐng)先模型相媲美。這一成績無疑是對騰訊研發(fā)團隊實力和創(chuàng)新能力的高度認可。
在架構(gòu)方面,Turbo S采用了Hybrid-Mamba-Transformer融合模式,這一創(chuàng)新設計不僅降低了傳統(tǒng)Transformer結(jié)構(gòu)的計算復雜度,還減少了KV-Cache緩存的占用,從而實現(xiàn)了訓練和推理成本的顯著降低。這一突破性的進展,使得Turbo S在應對長文訓練和推理時,能夠展現(xiàn)出更高的效率和更低的成本。
Turbo S的成功發(fā)布,標志著“工業(yè)界首次”將Mamba架構(gòu)無損地應用在超大型MoE模型上。這一技術(shù)創(chuàng)新不僅發(fā)揮了Mamba在處理長序列方面的優(yōu)勢,還保留了Transformer在捕捉復雜上下文方面的能力,從而構(gòu)建了一個顯存與計算效率雙優(yōu)的混合架構(gòu)。
作為騰訊混元系列的旗艦模型,Turbo S未來將成為衍生模型的核心基座,為推理、長文、代碼等衍生模型提供強大的基礎能力。基于Turbo S,騰訊還推出了具備深度思考能力的推理模型T1,通過引入長思維鏈、檢索增強和強化學習等技術(shù),進一步提升了模型的智能水平。
目前,開發(fā)者和企業(yè)用戶已經(jīng)可以在騰訊云上通過API調(diào)用Turbo S模型,享受其帶來的高效和便捷。騰訊還宣布,即日起一周內(nèi),用戶可免費試用Turbo S模型,以親身體驗其卓越的性能。
在定價方面,Turbo S也展現(xiàn)出了極高的性價比。其輸入價格為0.8元/百萬tokens,輸出價格為2元/百萬tokens,相比前代混元Turbo模型,價格下降數(shù)倍,這無疑將吸引更多用戶選擇和使用Turbo S模型。
騰訊元寶也將逐步灰度上線Turbo S模型。用戶在元寶內(nèi)選擇“Hunyuan”模型并關(guān)閉深度思考功能后,即可體驗使用Turbo S模型帶來的智能服務。