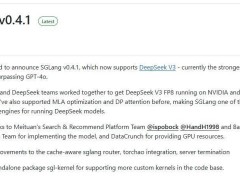
中國電信人工智能研究院近日宣布,其傾力打造的“復雜推理大模型”TeleAI-t1-preview已正式面世,并將很快在天翼AI開放平臺上與公眾見面。該模型采用先進的強化學習訓練技術,通過引入探索與反思機制,顯著提升了在邏輯推理與數學推導等復雜問題上的解答精度。
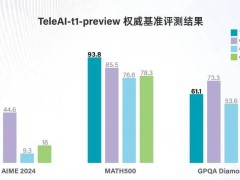
據官方介紹,TeleAI-t1-preview在美國數學競賽AIME 2024與MATH500兩項權威基準測試中,分別以60分和93.8分的優異成績,遠超OpenAI的o1-preview和GPT-4o等業界標桿模型。在研究生級別問答測試GPQA Diamond中,其表現同樣出色,得分超越GPT-4o,與Claude 3.5 Sonnet的性能不相上下。

評測顯示,TeleAI-t1-preview在處理《九章算術》中的題目時,能夠先對文言文進行精準理解和簡化,再轉換成現代漢語,并給出詳細的數學推導過程和答案。這一過程中,模型展現了將形象思維與抽象思維相結合的能力,對所涉及場景進行具象化思考,從而更好地理解題目。


尤為TeleAI-t1-preview還能嚴謹地進行古今單位換算,確保了答案的準確性。這一成就得益于中國電信人工智能研究院在模型訓練策略上的創新。
在數據準備階段,研究院收集并構建了一個以數學為核心、涵蓋多學科的高質量推理數據集,為模型適應不同類型推理任務打下了堅實基礎。還訓練了一個專門的Judge Model,用于分析和評估模型長思考鏈路的正確性,為模型的反思和錯誤修正提供精準指導。
在監督微調(SFT)階段,研究院采用蒙特卡洛樹搜索(MCTS)構造高質量長推理數據,結合每個步驟的準確率和解決方案長度,選擇最優完整路徑。這不僅保證了推理答案的準確性,還有效拉長了思考鏈路,使推理過程更加細粒度。同時,利用Judge Model對推理過程中正確率較低的路徑進行分析,引導模型對錯誤推理步驟進行反思和修正,從而構造出高質量的思維鏈數據進行SFT訓練。
在強化學習階段,研究院額外構造了基于規則的獎勵模型(Rule-based Reward Model),提供準確獎勵信號,通過在線強化學習算法進一步提升模型的邏輯推理能力。這一系列創新舉措,共同成就了TeleAI-t1-preview在復雜推理領域的卓越表現。