近期,大型語言模型(LLM)如ChatGPT等在處理與生成人類語言方面的能力顯著增強,但它們在多大程度上模擬了人類大腦處理語言的神經過程,仍是未解之謎。然而,一項由哥倫比亞大學和費因斯坦醫學研究所聯合開展的研究,為這一謎題提供了新的線索。
據報道,研究團隊深入探索了LLM與大腦神經反應之間的相似性。研究的主要推動者,論文第一作者加文?米施勒指出,他們的研究靈感源于LLM與神經AI領域的快速發展。米施勒在采訪中透露,盡管早期的研究表明GPT-2的詞嵌入與人腦對語言的神經反應存在某種程度的相似性,但GPT-2在當前人工智能領域已不再是領先者。
隨著ChatGPT等更強大的模型的出現,關于這些新模型是否依然表現出與人類大腦相似的特征,米施勒及其團隊展開了詳細的探究。他們選擇了12個在架構和參數數量上幾乎一致的開源LLM進行分析,同時,通過神經外科患者腦部植入的電極,記錄了他們聽到語言時的大腦反應。
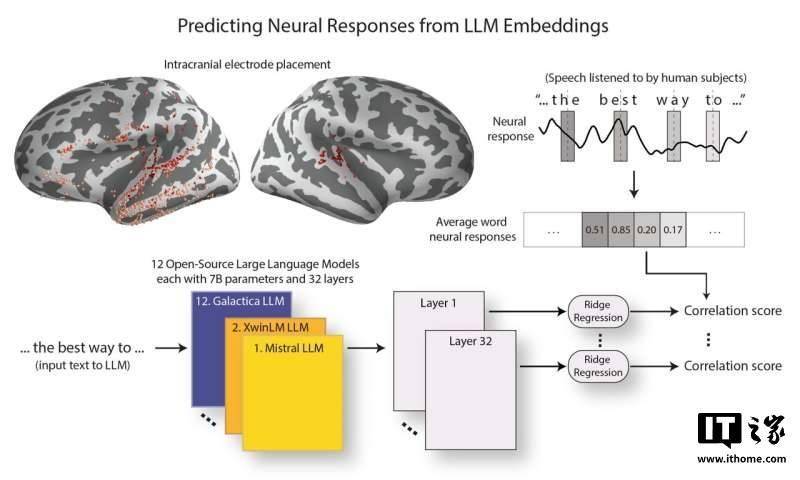
在研究中,米施勒團隊將相同的演講文本輸入LLM,并提取其詞嵌入,這些詞嵌入是模型內部用于處理和編碼文本的表示。為了衡量LLM與大腦的相似性,研究人員嘗試通過預測大腦對詞語反應的神經活動來評估兩者的對應性。他們利用計算工具分析了LLM與大腦的對齊程度,特別關注了哪些層次的LLM與大腦中與語言處理相關的區域最為匹配。
米施勒表示,研究發現,隨著LLM能力的提升,其詞嵌入與大腦對語言的反應越來越接近。更令人驚訝的是,模型性能的提升與其與大腦層次結構的對齊程度提高之間存在關聯。這意味著,在語言處理過程中,大腦不同區域提取的信息與性能較強的LLM的不同層次提取的信息更加一致。
這些研究結果表明,表現最好的LLM更能準確反映大腦的語言處理反應,并且這些模型的優秀表現可能與其早期層次的高效性密切相關。這一發現不僅揭示了LLM與人類大腦在語言處理方面的相似性,也為未來人工智能技術的發展提供了新的啟示。






















