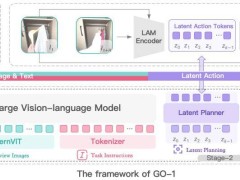
近日,由知名技術博主“稚暉君”發起的創業項目智元機器人,正式揭曉了其首個通用具身基座模型——智元啟元大模型(簡稱GO-1)。這款模型創新性地引入了Vision-Language-Latent-Action(ViLLA)架構,標志著具身智能領域的一次重要突破。
ViLLA架構的核心在于將VLM(多模態大模型)與MoE(混合專家)相結合。VLM部分借助廣泛的互聯網圖文數據,實現了對通用場景的深刻感知和語言理解。而MoE則包含Latent Planner(隱式規劃器)和Action Expert(動作專家)兩部分,前者通過大量跨本體和人類操作視頻數據,獲得了強大的動作規劃能力;后者則依托百萬真機數據,具備了精細的動作執行能力。
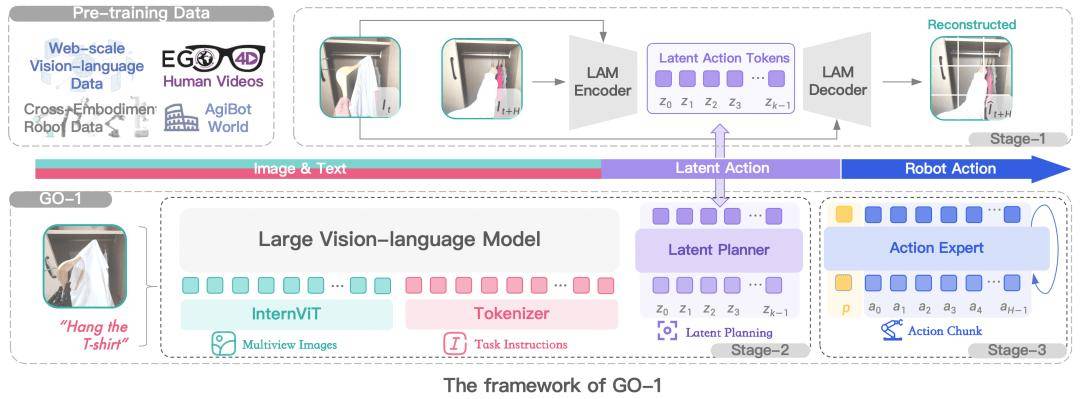
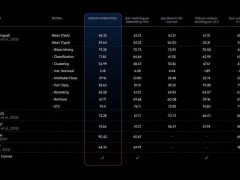
智元機器人在五種不同復雜度的任務上對GO-1進行了測試,結果顯示,相比現有的最優模型,GO-1的平均成功率提高了32%,從46%躍升至78%。特別是在“倒水”、“清理桌面”和“補充飲料”等任務中,GO-1的表現尤為出色。單獨驗證Latent Planner的作用時發現,增加Latent Planner可使成功率提升12%,從66%提高至78%。
GO-1大模型不僅具備強大的學習和泛化能力,還能從人類和多種機器人數據中汲取知識,快速適應新任務和學習新技能。它支持部署到不同的機器人本體上,實現真正的“一腦多形”。這意味著GO-1可以在不同形態的機器人之間遷移,快速適配,實現群體智能的提升。
更令人稱道的是,GO-1大模型還具備持續進化的能力。借助智元提供的數據回流系統,GO-1可以從實際執行中遇到的問題數據中不斷學習和進化,越用越聰明。這一特性極大地降低了具身模型的使用門檻,使得后訓練成本大幅降低。
智元機器人在發布會上還預告了下一代具身智能機器人產品,但并未透露具體的推出時間。這一消息無疑為行業內外帶來了更多的期待和想象空間。

GO-1大模型的成功發布,標志著智元機器人在具身智能領域取得了重要的階段性成果。未來,隨著技術的不斷演進和應用的不斷拓展,GO-1有望在更多領域發揮重要作用,為人類社會帶來更加智能、便捷的服務。