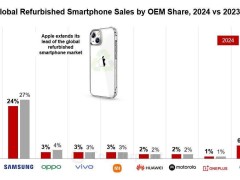
近日,DeepSeek在其備受矚目的“開源周”活動中,迎來了第二天的重要發布——DeepEP,這是一個專為混合專家(MoE)模型訓練和推理設計的開源EP通信庫。
DeepEP的開源地址已經公布,感興趣的開發者和研究人員可以訪問此鏈接獲取更多信息。
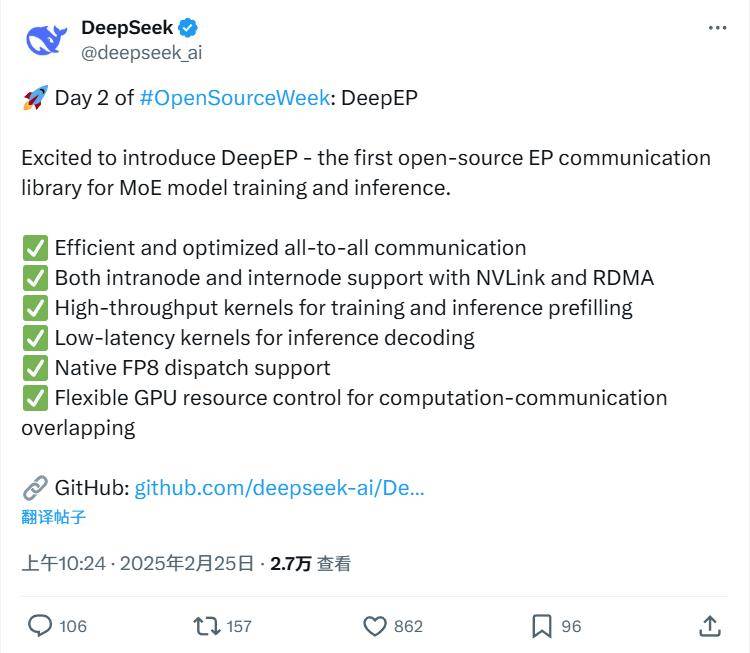
據官方介紹,DeepEP具備多項顯著特征,使其成為處理MoE模型時的理想選擇。首先,它采用了高效優化的全到全通信方式,確保了數據傳輸的高效性。其次,DeepEP支持節點內外的通信,并且兼容NVLink和RDMA技術,這為用戶提供了更多的靈活性和兼容性。
DeepEP還提供了高吞吐量的內核,這些內核在訓練和推理的前期填充階段能夠顯著提升效率。同時,對于推理解碼任務,DeepEP則提供了一套低延遲內核,這些內核采用純RDMA技術,最大限度地減少了延遲,從而優化了推理解碼速度。
DeepEP完全支持FP8數據格式的調度,這對于低精度計算的需求來說無疑是一個重要的優勢。該庫還提供了靈活的GPU資源管理功能,支持計算與通信的重疊執行,這進一步提高了資源利用效率和整體性能。
DeepEP的設計初衷是為了滿足混合專家(MoE)和專家并行(EP)模型的特殊需求。它提供了高吞吐量和低延遲的all-to-all GPU內核,這些內核常用于MoE的派發和合并操作。為了與DeepSeek-V3論文中提出的組限制門控算法兼容,DeepEP還進行了一些針對不對稱帶寬轉發優化的內核設計。
例如,它能夠將數據從NVLink域轉發到RDMA域,這些優化的內核提供了高吞吐量,非常適合用于訓練和推理的預填充任務。同時,DeepEP還支持SM(流式多處理器)數量控制,這為用戶提供了更多的控制和靈活性。
對于延遲敏感型的推理解碼任務,DeepEP的低延遲內核無疑是一個重要的亮點。這些內核采用純RDMA技術,最大限度地減少了延遲,從而確保了推理解碼任務的高效執行。DeepEP還采用了一種基于Hook的通信與計算重疊方法,這種方法不會占用任何SM資源,進一步提高了整體性能。
當然,要使用DeepEP,還需要滿足一些硬件和軟件的要求。例如,需要配備Hopper GPUs(未來可能會支持更多架構或設備),以及Python 3.8及以上版本、CUDA 12.3及以上版本和PyTorch 2.1及以上版本。還需要使用NVLink或基于RDMA網絡的節點間通信。