近期,智源研究院揭曉了一項涉及國內(nèi)外100多個開源與商業(yè)閉源大模型的全面評測結(jié)果,引起了業(yè)界的廣泛關(guān)注。在備受矚目的大語言模型評測能力榜單中,一款名為豆包通用模型pro(Doubao-pro-32k-preview)的國產(chǎn)大模型,在主觀評測環(huán)節(jié)脫穎而出,榮獲榜首。
據(jù)悉,智源研究院的Flageval評測平臺,已納入全球超過800個開閉源大模型,并與國內(nèi)十余所高校及機(jī)構(gòu)合作,共同構(gòu)建評測方法與工具。此次評測中,大語言模型的主觀評測尤為注重模型的中文處理能力。豆包通用模型pro憑借其卓越表現(xiàn),贏得了專家評審團(tuán)的高度認(rèn)可。
不僅如此,在多模態(tài)模型評測榜單的視覺語言模型分類中,豆包·視覺理解模型(Doubao-Pro-Vision-32k-241028)同樣表現(xiàn)出色,僅次于GPT-4,成為得分最高的國產(chǎn)大模型。這一成績不僅彰顯了豆包大模型在視覺語言理解領(lǐng)域的深厚實(shí)力,也為其在更多應(yīng)用場景中的拓展奠定了堅實(shí)基礎(chǔ)。
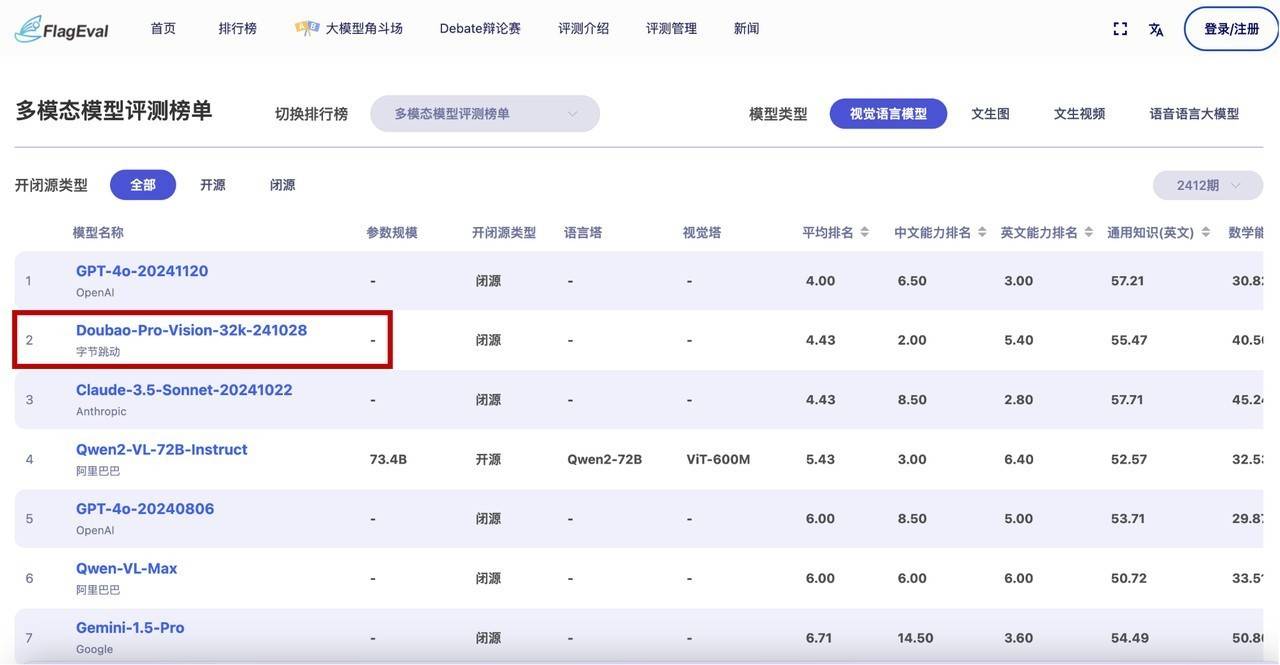
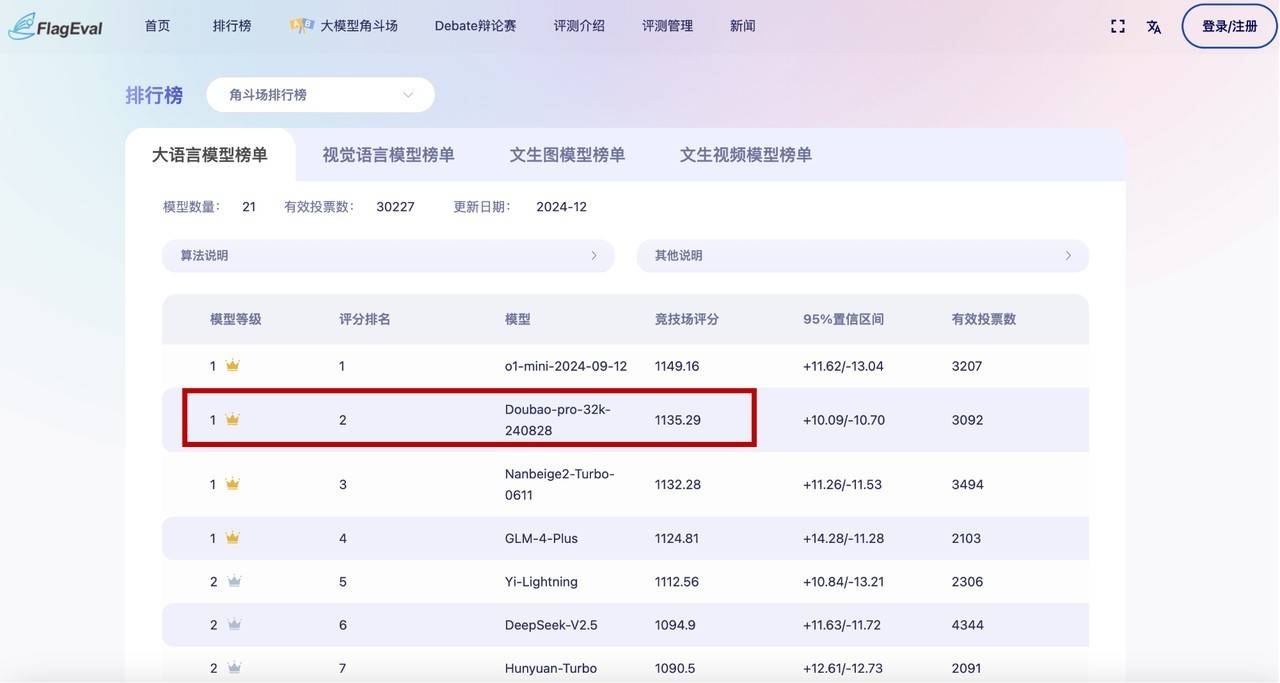
在Flageval大模型角斗場榜單中,豆包通用模型pro同樣不負(fù)眾望,位居大語言模型榜單的第二名,僅次于OpenAI的o1-mini。這一成績再次證明了豆包大模型在業(yè)界的領(lǐng)先地位,以及其在處理復(fù)雜語言任務(wù)方面的卓越能力。
隨著使用量的不斷攀升,豆包大模型也迎來了全新的升級。數(shù)據(jù)顯示,自今年5月發(fā)布以來,豆包大模型的日均tokens使用量已超過4萬億,增長了33倍之多。這一增長不僅推動了豆包大模型在不同應(yīng)用場景中的廣泛應(yīng)用,也為其性能的持續(xù)優(yōu)化提供了有力支撐。
此次升級后,豆包通用模型pro在綜合處理能力上提升了32%,推理能力提升了13%,指令遵循能力提升了9%,代碼處理能力提升了58%,數(shù)學(xué)能力提升了43%,專業(yè)知識領(lǐng)域能力也提升了54%。這一系列顯著的提升,使得豆包大模型在處理復(fù)雜任務(wù)時更加游刃有余。

與此同時,豆包·視覺理解模型也在FORCE原動力大會上正式對外發(fā)布。該模型能夠理解用戶輸入的文本和圖片信息,并給出準(zhǔn)確的回答。憑借其強(qiáng)大的內(nèi)容識別、理解和推理能力,以及細(xì)膩的視覺描述能力,豆包·視覺理解模型在教育、旅游、電商等場景中具有廣泛的應(yīng)用前景。
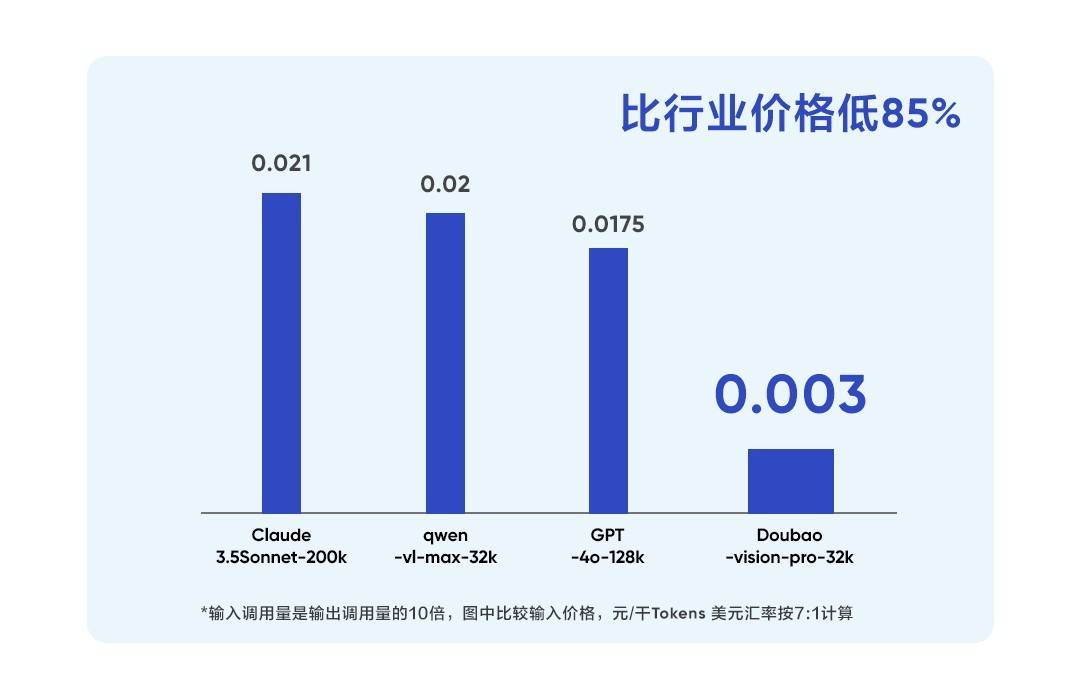
為了更好地幫助企業(yè)開拓大模型的創(chuàng)新應(yīng)用場景,豆包·視覺理解模型還提供了極具競爭力的價格。每千tokens僅需0.003元,比行業(yè)平均價格降低了85%。這一舉措無疑將大大降低企業(yè)使用大模型的門檻,推動AI大模型應(yīng)用的普及與落地。























