網(wǎng)絡安全領(lǐng)域近期迎來了一起引人矚目的發(fā)現(xiàn):在知名機器學習平臺HuggingFace上,兩個看似普通的機器學習模型實則暗藏玄機。這些模型采用了一種前所未有的技術(shù)——通過“破壞”pickle文件,巧妙地規(guī)避了安全系統(tǒng)的檢測。
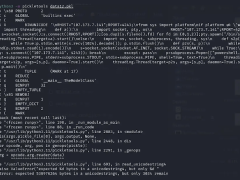
據(jù)網(wǎng)絡安全研究員Karlo Zanki透露,這兩個PyTorch存檔中的pickle文件,在文件頭部竟然隱藏著惡意的Python代碼。這些惡意載荷均為針對特定平臺的反向shell,旨在連接到預設的IP地址。

這種新型攻擊手段被命名為nullifAI,其核心在于繞過現(xiàn)有的安全防護,使惡意模型難以被識別。涉及的兩個模型存儲庫分別為glockr1/ballr7和who-r-u0000/一串長數(shù)字組成的名稱,它們更像是對該技術(shù)的概念驗證,而非實際應用于供應鏈攻擊。
pickle序列化格式在機器學習模型的分發(fā)過程中極為常見,但其安全性一直備受質(zhì)疑。由于pickle允許在加載和反序列化時執(zhí)行任意代碼,因此成為了潛在的安全隱患。這兩個被發(fā)現(xiàn)的模型雖然采用PyTorch格式,但實質(zhì)上是以7z壓縮的pickle文件,這與PyTorch默認的ZIP格式不同,從而成功規(guī)避了Hugging Face平臺上Picklescan工具的惡意檢測。
Zanki進一步分析指出,這些pickle文件的獨特之處在于,對象序列化在惡意載荷執(zhí)行后會中斷,導致無法正確反編譯對象。然而,后續(xù)研究表明,盡管存在反序列化錯誤,這些“損壞”的pickle文件仍能被部分反序列化,進而執(zhí)行其內(nèi)置的惡意代碼。
值得慶幸的是,該安全問題已經(jīng)得到及時修復,Picklescan工具也已更新版本,增強了其檢測能力。這一發(fā)現(xiàn)再次提醒了機器學習社區(qū),對于pickle文件的安全使用需保持高度警惕。