1月27日凌晨,阿里云通義重磅開源支持100萬Tokens上下文的Qwen2.5-1M模型,推出7B及14B兩個尺寸,均在處理長文本任務中穩定超越GPT-4o-mini;同時開源推理框架,在處理百萬級別長文本輸入時可實現近7倍的提速。

百萬Tokens長文本,可換算成10本長篇小說、150小時演講稿或3萬行代碼。兩個月前, Qwen2.5-Turbo 升級了百萬Tokens的上下文輸入能力,廣受開發者和企業歡迎。如今,開源社區可基于全新的 Qwen2.5-1M 系列模型,進行長篇小說或多篇學術論文的解析,或是探索倉庫級代碼的分析和升級。
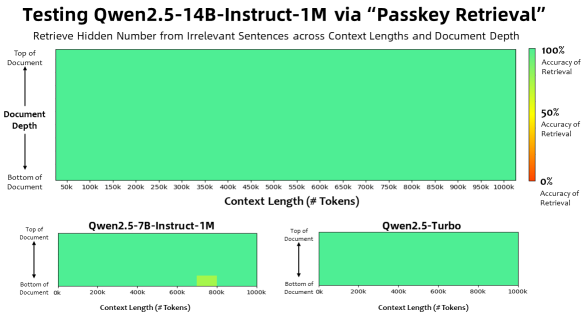
Qwen2.5-1M擁有優異的長文本處理能力。在上下文長度為100萬 Tokens 的大海撈針(Passkey Retrieval)任務中,Qwen2.5-1M 能夠準確地從 1M 長度的文檔中檢索出隱藏信息,僅有7B模型出現了少量錯誤。在RULER、LV-eval等基準對復雜長上下文理解任務測試中,Qwen2.5-14B-Instruct-1M 模型不僅擊敗了自家閉源模型 Qwen2.5-Turbo,還穩定超越 GPT-4o-mini,為開發者提供了一個現有長上下文模型的優秀開源替代。
大模型的長文本訓練需要消耗大量的計算資源,通義團隊通過逐步擴展長度的方法,從預訓練到監督微調再到強化學習等多個階段,高效地將 Qwen2.5-1M 的上下文長度從 4K 擴展到 256K;再通過長度外推的技術,創新引入Dual Chunk Attention機制,在無需額外訓練的情況下,將上下文長度高性能地穩定擴展到1M,從而在較低成本下實現了 Qwen2.5-1M 模型。
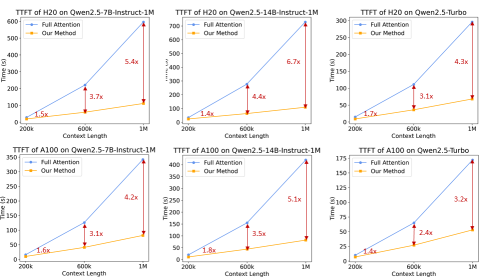
同時,為了加快推理速度,通義團隊在vLLM推理引擎基礎上,引入基于Minference的稀疏注意力機制,并在分塊預填充、集成長度外推方案和稀疏性優化等多環節創新改進。基于這些改進的推理框架有效地加快了模型推理速度,在不同模型大小和 GPU 設備上,處理 1M 長度輸入序列的預填充速度提升了 3.2 倍到 6.7 倍。
據了解,Qwen2.5-1M已經在魔搭社區ModelScope和HuggingFace等平臺開源,開發者可前往下載或直接體驗模型;相關推理框架也已在GitHub上開源,幫助開發者更高效地部署Qwen2.5-1M模型。開發者和企業也可通過阿里云百煉平臺調用 Qwen2.5-Turbo 模型API,或是通過全新的Qwen Chat平臺體驗模型性能及效果。
附鏈接:
演示Demo:https://www.modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
Modelscope:https://www.modelscope.cn/organization/Qwen
Huggingface:https://huggingface.co/Qwen
開源框架地址:https://github.com/QwenLM/vllm/tree/dev/dual-chunk-attn
Qwen Chat體驗:https://chat.qwenlm.ai/