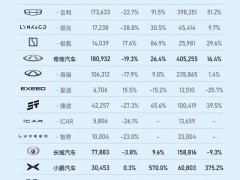
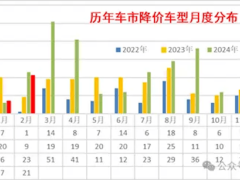
近期,字節跳動旗下豆包大模型團隊傳來喜訊,他們在混合專家(MoE)架構領域取得了重大技術革新,并慷慨決定將此技術成果向全球AI社區開放。
這項創新技術通過一系列巧妙設計,顯著提升了大型模型的訓練效率,增幅達到了約1.7倍。與此同時,它還極大地降低了訓練成本,成本降幅高達40%。這一突破無疑為大規模模型訓練領域帶來了更為高效和經濟的新方案。
據悉,字節跳動已在內部萬卡集群訓練中成功應用了該技術。據統計,自采用以來,該技術已幫助公司節省了數以百萬計的GPU小時訓練算力。這一實際應用成果不僅驗證了技術的卓越效果,也再次彰顯了字節跳動在AI技術研發領域的卓越實力。
豆包大模型團隊此次開源的決定,旨在通過技術共享,促進整個AI社區在模型訓練效率方面的共同提升。他們相信,開源將有助于加速行業技術發展,并為全球范圍內的研究者和開發者提供寶貴的資源,進一步推動人工智能技術的創新與應用。

對于AI社區的廣大成員而言,這無疑是一個振奮人心的消息。他們將有機會深入研究和應用這一先進技術,從而推動人工智能領域的發展邁向新的高度。而字節跳動的這一開源舉措,也將為他們提供強有力的技術支持和資源保障。