Hugging Face平臺近日宣布了一項重大進展,推出了兩款專為算力受限設備設計的輕量級AI模型——SmolVLM-256M-Instruct與SmolVLM-500M-Instruct。這兩款模型的問世,標志著在資源有限的環境下,AI性能發揮將邁入新階段。
早在去年11月,Hugging Face就已推出了僅有20億參數的SmolVLM AI視覺語言模型,該模型因其極低的內存占用而在同類產品中表現突出,特別適用于設備端推理。而此次推出的新版本,則在參數數量上進行了進一步優化。
SmolVLM-256M-Instruct,作為目前發布的最小視覺語言模型,其參數量僅為2.56億。令人驚嘆的是,這款模型甚至能在內存低于1GB的PC上流暢運行,同時提供出色的性能表現。這無疑為那些擁有有限硬件資源的用戶和開發者打開了全新的可能性。
另一款模型SmolVLM-500M-Instruct,則擁有5億參數。它主要針對硬件資源受限的場景設計,旨在幫助開發者應對大規模數據分析的挑戰,實現AI處理效率和可訪問性的雙重突破。這兩款模型的推出,無疑將進一步提升Hugging Face在AI領域的競爭力。
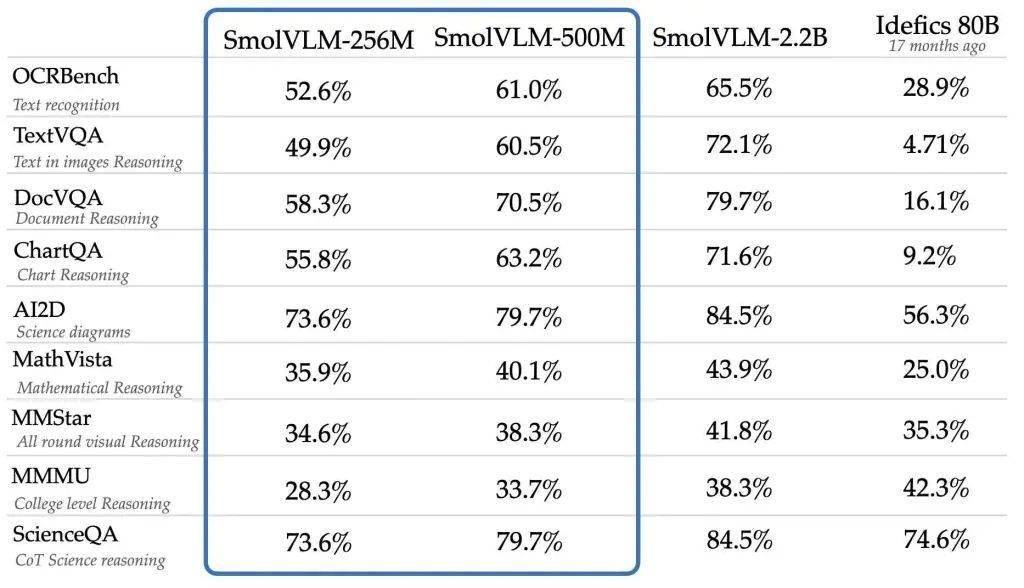
SmolVLM系列模型具備先進的多模態能力,能夠執行包括圖像描述、短視頻分析以及回答關于PDF或科學圖表問題在內的多項任務。Hugging Face解釋稱,SmolVLM在構建可搜索數據庫時速度更快、成本更低,其性能甚至可媲美規模遠超其自身的模型。
為了開發這些模型,Hugging Face采用了兩個專有數據集:The Cauldron和Docmatix。The Cauldron是一個包含50個高質量圖像和文本數據集的精選集合,專注于多模態學習。而Docmatix則專為文檔理解而設計,通過將掃描文件與詳細標題配對,以增強模型的理解能力。
在模型架構方面,SmolVLM-256M-Instruct和SmolVLM-500M-Instruct采用了更小的視覺編碼器SigLIP base patch-16/512,而非SmolVLM 2B中使用的更大版本SigLIP 400M SO。這一優化減少了冗余,提高了模型處理復雜數據的能力,并優化了圖像標記的處理方式。
SmolVLM系列模型能夠以每個標記4096像素的速率對圖像進行編碼,這一性能相較于早期版本中的每標記1820像素有了顯著提升。這一改進將進一步增強模型在圖像處理和理解方面的能力。