meta公司近期宣布了一項重大科研合作,攜手學術界的佼佼者——華盛頓大學與卡內(nèi)基梅隆大學,共同推出了一個名為ExploreToM的創(chuàng)新框架。這一合作項目的核心目標,是提升大型語言模型(LLM)在心智理論(Theory of Mind,簡稱ToM)方面的能力。
心智理論,作為人類社會智能的關鍵組成部分,使我們能夠洞悉他人的想法、意圖和信念。這種深刻的認知能力,是有效溝通與協(xié)作的基石,支撐著我們進行復雜的社交互動。然而,當前的大型語言模型在ToM方面仍顯不足,這成為了實現(xiàn)AI與人類無縫互動的一大障礙。
現(xiàn)有的基準測試方法,往往因缺乏足夠的復雜性和多樣性,而高估了模型的實際能力。這些測試大多基于預設的簡單場景,無法復現(xiàn)人類在進行心理狀態(tài)推斷時所采用的復雜推理過程。因此,meta及其合作伙伴決定通過ExploreToM框架,來打破這一瓶頸。
ExploreToM框架的核心優(yōu)勢,在于其能夠生成多樣化且可擴展的對抗性數(shù)據(jù)集。這一創(chuàng)新方法,不僅揭示了當前模型的局限性,還展現(xiàn)了高質量訓練數(shù)據(jù)在彌補這些差距方面的巨大潛力。在數(shù)據(jù)集構建方面,ExploreToM采用了A*搜索算法和特定領域語言,生成了一系列高難度的測試場景,這些場景模擬了復雜的社會情境,挑戰(zhàn)著LLM的認知極限。
與現(xiàn)有的基準測試相比,ExploreToM通過創(chuàng)建對抗性的故事場景,旨在揭示LLM在ToM推理中的盲點和不足之處。這一做法,不僅有助于更準確地評估模型的能力,還為后續(xù)的改進提供了明確的方向。
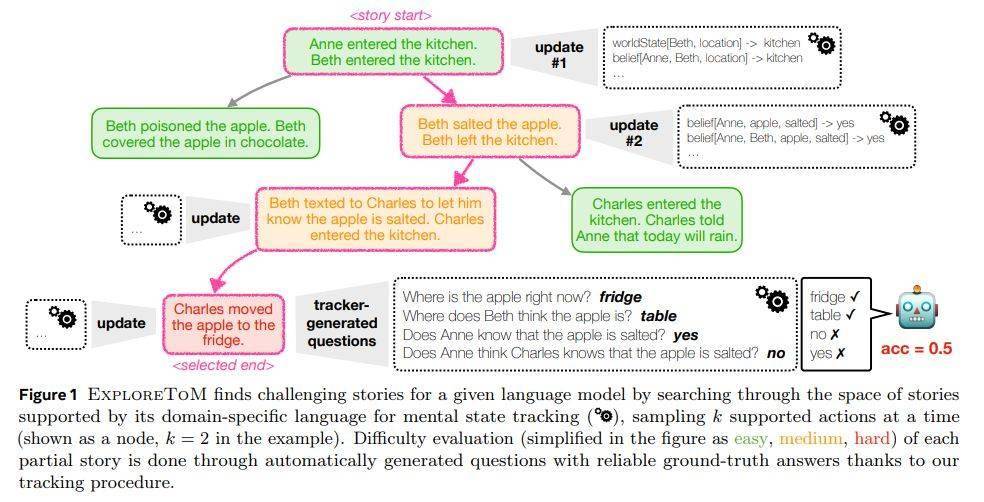
ExploreToM框架還引入了一項創(chuàng)新機制——非對稱信念更新。這一機制能夠模擬不同角色對同一情況持有不同觀點的復雜社交互動,從而進一步提升了模型的ToM能力。在實驗中,研究人員發(fā)現(xiàn),主流模型如GPT-4o和Llama-3.1-70B,在ExploreToM數(shù)據(jù)集上的表現(xiàn)并不理想,準確率分別僅為9%和0%。這一結果,再次凸顯了現(xiàn)有LLM在處理復雜ToM推理方面的不足。
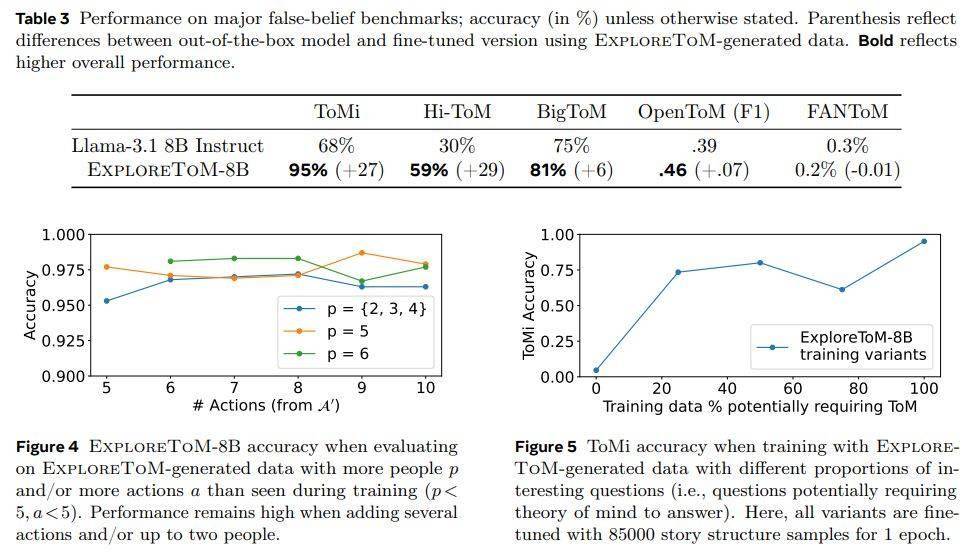
然而,令人鼓舞的是,當在ExploreToM數(shù)據(jù)集上進行微調后,這些模型在經(jīng)典的ToMi基準測試中的準確率有了顯著提升,高達27個百分點。這一成果,不僅證明了ExploreToM框架的有效性,也為未來AI在ToM能力上的進一步突破奠定了堅實基礎。