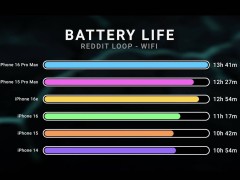
近日,科技界傳來一則新進展,騰訊AI Lab與香港中文大學攜手,在大型語言模型推理效率方面取得了突破。他們提出了一項名為“無監督前綴微調”(UPFT)的創新技術,為提升語言模型的推理能力提供了新的思路。
UPFT技術的核心在于,它并不需要對整個推理過程進行全面處理,而是聚焦于模型輸出的前幾個詞元(token),具體而言,是前8至32個詞元。這一方法巧妙地捕捉到了不同推理路徑中的共同早期關鍵步驟,從而在減少計算開銷的同時,實現了推理性能的提升。這一發現無疑為大型語言模型的優化帶來了新的曙光。
眾所周知,大型語言模型在語言理解和生成方面已經展現出了強大的能力,但在推理方面仍有待提升。傳統的微調方法往往需要依賴大量的標注數據或復雜的拒絕采樣技術,這無疑增加了資源消耗的難度。而UPFT則打破了這一局限,它通過關注模型輸出的初始詞元,有效地解決了效率和對昂貴監督的依賴問題。
研究發現,對于同一個問題,模型生成的各種推理路徑的初始步驟往往具有很高的相似性。UPFT正是基于這種“前綴自洽性”原理,無需完整的推理軌跡或大量的標注數據,僅通過這些初始標記進行訓練,便能夠取得顯著的效果。
UPFT技術還巧妙地融合了貝葉斯推理原理,將正確推理的概率分解為“覆蓋率”和“準確性”兩部分。通過訓練早期詞元,UPFT在探索多樣化的推理路徑的同時,確保了結果的可靠性。實驗數據表明,UPFT技術能夠顯著減少訓練中處理的詞元數量,最高可達95%,并大幅降低時間和內存需求。
在GSM8K、MATH500、AIME2024和GPQA等推理基準測試中,UPFT展現出了卓越的性能。特別是在Qwen2.5-Math-7B-Instruct模型上,UPFT在減少訓練和推理詞元數量的同時,還提升了平均準確率。在復雜推理任務中,UPFT的性能提升尤為明顯,這進一步證明了早期推理步驟中蘊含著解決問題的關鍵信息。
這一創新成果不僅為大型語言模型的優化提供了新的方向,也為人工智能領域的未來發展注入了新的活力。我們有理由相信,隨著技術的不斷進步和創新,人工智能將在更多領域展現出更加廣泛的應用前景。